Disaster Recovery Plan (DRP)



It is essential for a company to guarantee business continuity. To do so, it needs a robust disaster recovery plan that allows it to remain operational in the face of natural disaster or malicious attacks.
The Deyel Cloud infrastructure on AWS mainly bases its DRP strategy on the advantages offered by the AWS services on which it is mounted.
The two main axes of these advantages are the use of regions, availability zones and data centers distributed around the world, and the configuration of the services used to make use of this global infrastructure..
Use of AWS Regions, Availability Zones, and Data Centers
The Deyel Cloud infrastructure is based on AWS regions and availability zones.
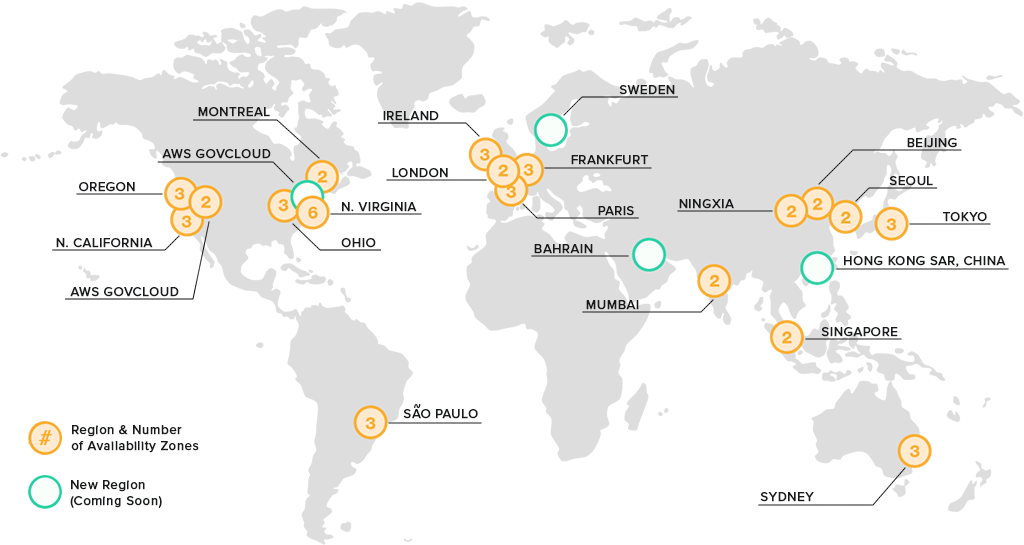
An AWS Region is a physical location in the world, which has multiple Availability Zones. These zones have one or more data centers, each with power, networks and connectivity.
These availability zones provide the ability to operate highly available, fault-tolerant, and scalable database and production applications. AWS has more than 100 availability zones and more than 30 geographic regions around the world.
https://www.infrastructure.aws/
Each AWS region is designed to be completely isolated from the other regions. This allows for greater fault tolerance and stability. Each availability zone is isolated, even though they are connected through low-latency links.
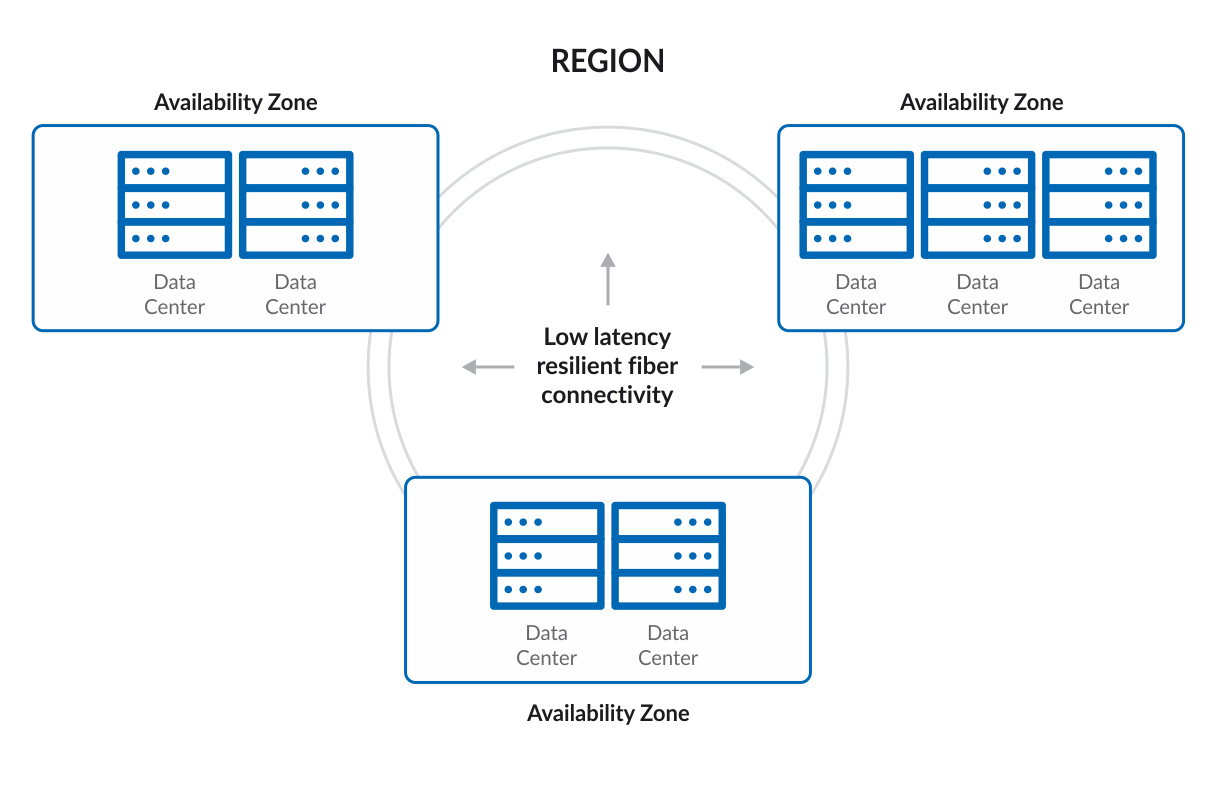
Each availability zone is designed as a separate fault zone, meaning that availability zones are physically separated within a typical metropolitan region and located on low-risk flood plains.
They also have uninterruptible power supplies (UPS) and onsite backups. Availability zones are connected with high-speed links (tier-1).
Configuration of AWS Services Used by Deyel Cloud to Use the Global Infrastructure
AWS services used in Deyel Cloud infrastructure are configured to use regions and availability zones.
Main Components of Deyel Cloud Infrastructure
The main components of Deyel Cloud infrastructure and how the AWS services that support them are configured are detailed below.
•Application data
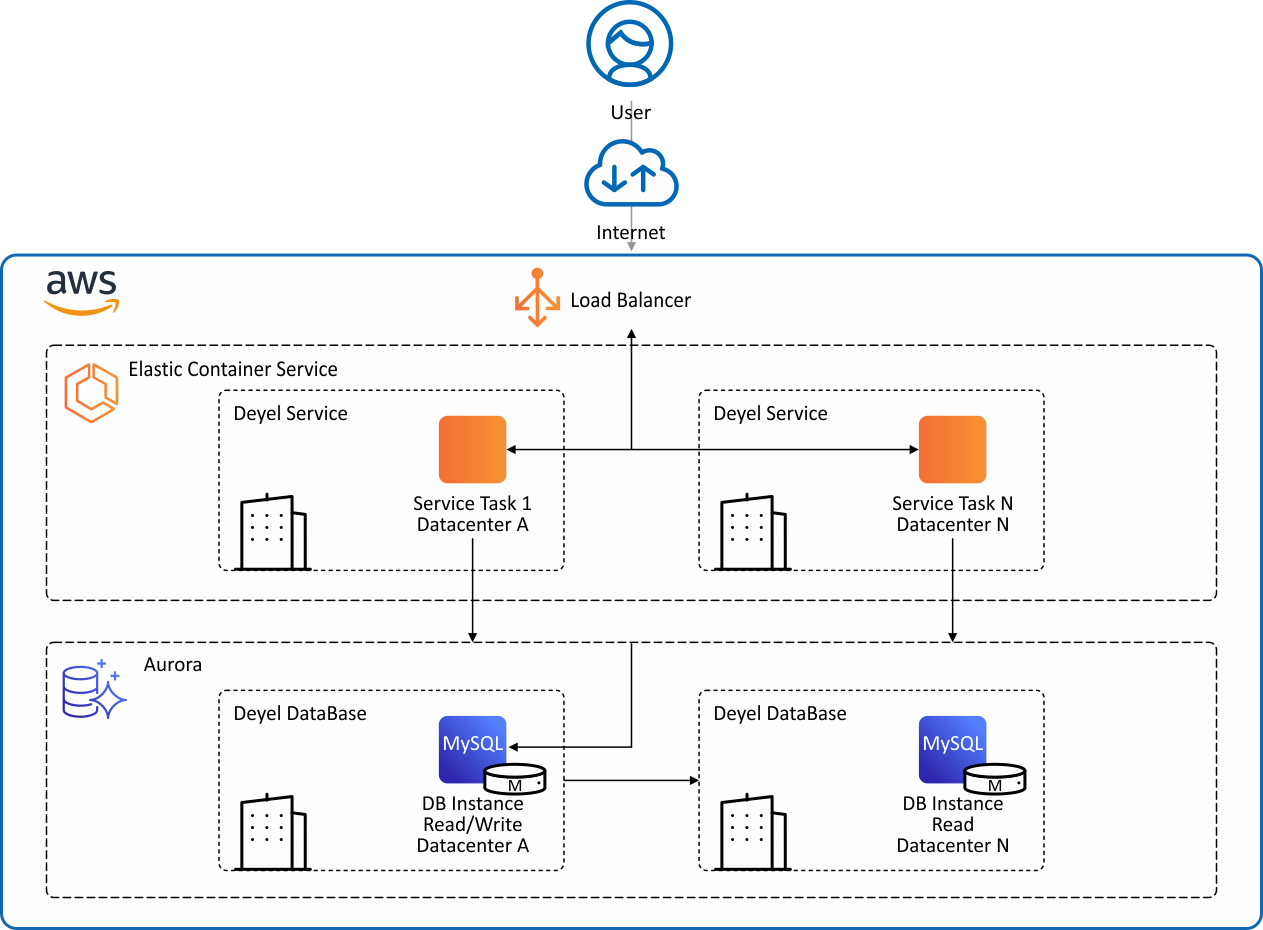
| Application data is stored in Amazon Relational Database (RDS) service Aurora clusters. These clusters are configured with read/write and read instances in different availability zones, which can be immediately swapped in the event of a failover. |
| To create backups, use the multiAZ option. |
•Execution of applications
| Applications are executed on AWS Elastic Container Service (ECS) clusters with EC2 instances distributed across availability zones, with autoscaling. Applications are executed on ECS services and can be multitask distributed across EC2 instances in different availability zones. |
| Clusters used by the Deyel Cloud infrastructure can be created in any AWS region globally in a matter of seconds. |
•Critical infrastructure files replicated among regions.
| All the files necessary for assembly and creation infrastructure and for a disaster recovery are stored with AWS S3 and Amazon ECR service, using replication among regions. |
•Infrastructure as code (IaC)
The infrastructure and resources necessary for the execution of Deyel on AWS are created using the AWS CloudFormation service. Using this service complies with the good practices of standardizing infrastructure components and allows fast troubleshooting.
It provides applications resources in a safe and repeatable way, allowing you to create and recreate infrastructure and applications, without having to perform manual actions or write custom scripts.
Through this service, the Deyel Cloud infrastructure and its applications can be implemented in any AWS region globally.
RPO, RTO and failure events for Standard and Enterprise Editions
Tasks and database with their replica are in different availability zones (in one or more data centers) within a region.
Failure Event |
Action |
RPO |
RTO |
|---|---|---|---|
The server executing the application goes out of service. Example: hardware failure, motherboard, fonts, disks, etc. |
If there are multiple application tasks, the load is shifted to the rest of the tasks. In all cases, an identical task is automatically started on another server in the same data center. |
0 |
In the Enterprise edition the RTO is 0.
In the Standard edition the RTO is less than 90 seconds. |
The data center that contains the servers executing the application goes out of service service. Example: catastrophe in the data center city. |
If there are multiple application tasks, the load is shifted to the rest of the tasks. In all cases, an identical task is automatically started on another server in the same data center. |
0 |
In the Enterprise edition the RTO is 0.
In the Standard edition the RTO is less than 90 seconds. |
The server executing the database goes out of service. Example: hardware failure, motherboard, fonts, disks, etc. |
The read-only instance is automatically converted to R/W. |
0 |
In both editions the RTO is less than 90 seconds. |
The R/W database goes out of service (structure breaks, engine problems). |
The read-only instance is automatically converted to R/W. |
0 |
In both editions the RTO is less than 90 seconds. |
Read Replica Instance in a Region Different from the Main One
The read replica instance in a region different from the main one is another option for higher availability and fault tolerance.
When considering catastrophes of global magnitude where an entire region may stop operating, clusters are generated through the AWS CloudFormation service in another region while maintaining use of the interregional database, achieving an active synchronization and a higher fault tolerance based on a better geographic dispersion.
The minimum essential RTO is 3 hours, although customer verification tasks are recommended before enabling the use of the platform again, which can raise the overall RTO.
As an example, to do lists for these cases are detailed.
Tasks |
RTO < 8 hours |
|---|---|
Assessing the situation, verification of the non-operating regions where the platform was operating. |
2hs |
Generating the platform infrastructure in the third region. |
Less than 30 minutes |
Configuring the new infrastructure with the operational database in this region. |
Less than 30 minutes |
Customer verification of the platform. |
Recommended. 3hs |




