Plan de Recuperación de Desastre (DRP)



Es fundamental para una empresa garantizar la continuidad del negocio. Para ello, necesita un plan sólido de recuperación ante desastres, que le permita mantenerse en funcionamiento frente a un desastre natural o ataques malintencionados.
La infraestructura Deyel Cloud en AWS, basa principalmente su estrategia del DRP, en las ventajas que ofrecen los servicios de AWS sobre los que está montada.
Los dos ejes principales de estas ventajas son la utilización de las regiones, zonas de disponibilidad y data centers distribuidos en el mundo, y la configuración de los servicios utilizados para que hagan uso de esta infraestructura global.
Utilización de Regiones, Zonas de Disponibilidad y Data Centers de AWS
La infraestructura Deyel Cloud se basa en regiones y zonas de disponibilidad de AWS.
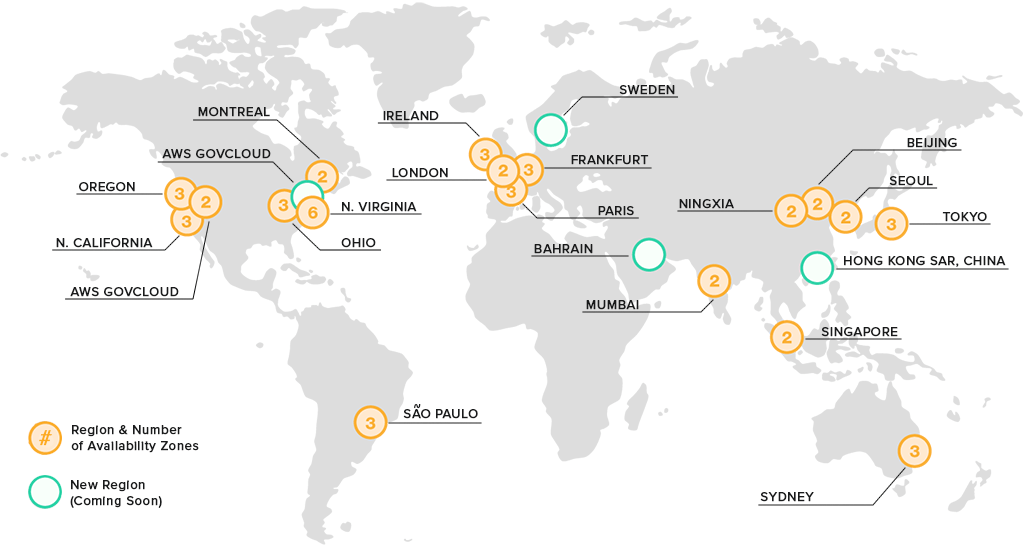
Una región de AWS es una ubicación física en el mundo, que tiene múltiples zonas de disponibilidad (Availability Zones). Estas zonas cuentan con uno o más data centers y cada uno de ellos con alimentación, redes y conectividades.
Estas zonas de disponibilidad ofrecen la capacidad de operar aplicaciones de producción y bases de datos con alta disponibilidad, tolerantes a fallas y escalables. AWS cuenta con más de 100 zonas de disponibilidad y con más de 30 regiones geográficas alrededor del mundo.
https://www.infrastructure.aws/
Cada región de AWS está diseñada para estar completamente aislada de las demás regiones. Esto permite mayor tolerancia a fallas y estabilidad. Cada zona de disponibilidad está aislada, aunque se encuentren conectadas a través de enlaces de baja latencia.
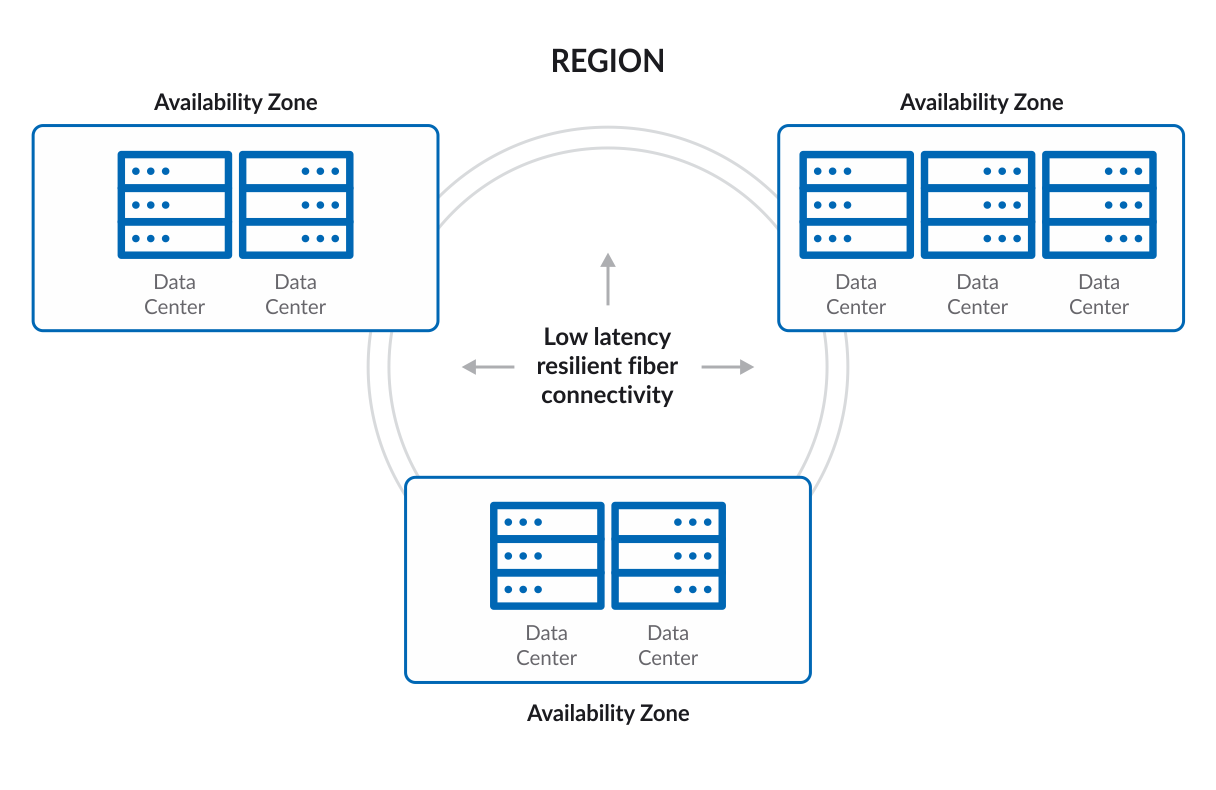
Cada zona de disponibilidad está diseñada como una zona de falla independiente, esto significa que las zonas de disponibilidad están físicamente separadas dentro de una región metropolitana típica y están ubicadas en llanuras con poco riesgo de inundación.
Además cuentan con fuentes de alimentación ininterrumpida (UPS) y backups onsite. Las zonas de disponibilidad se encuentran conectadas con enlaces de alta velocidad (tier-1).
Configuración de los Servicios de AWS Usados por Deyel Cloud para que Utilicen la Infraestructura Global
Los servicios de AWS utilizados en la infraestructura Deyel Cloud están configurados para utilizar regiones y zonas de disponibilidad.
Principales Componentes de Infraestructura Deyel Cloud
Se detallan a continuación los principales componentes de la infraestructura Deyel Cloud y cómo están configurados los servicios de AWS que los soportan.
•Datos de las aplicaciones
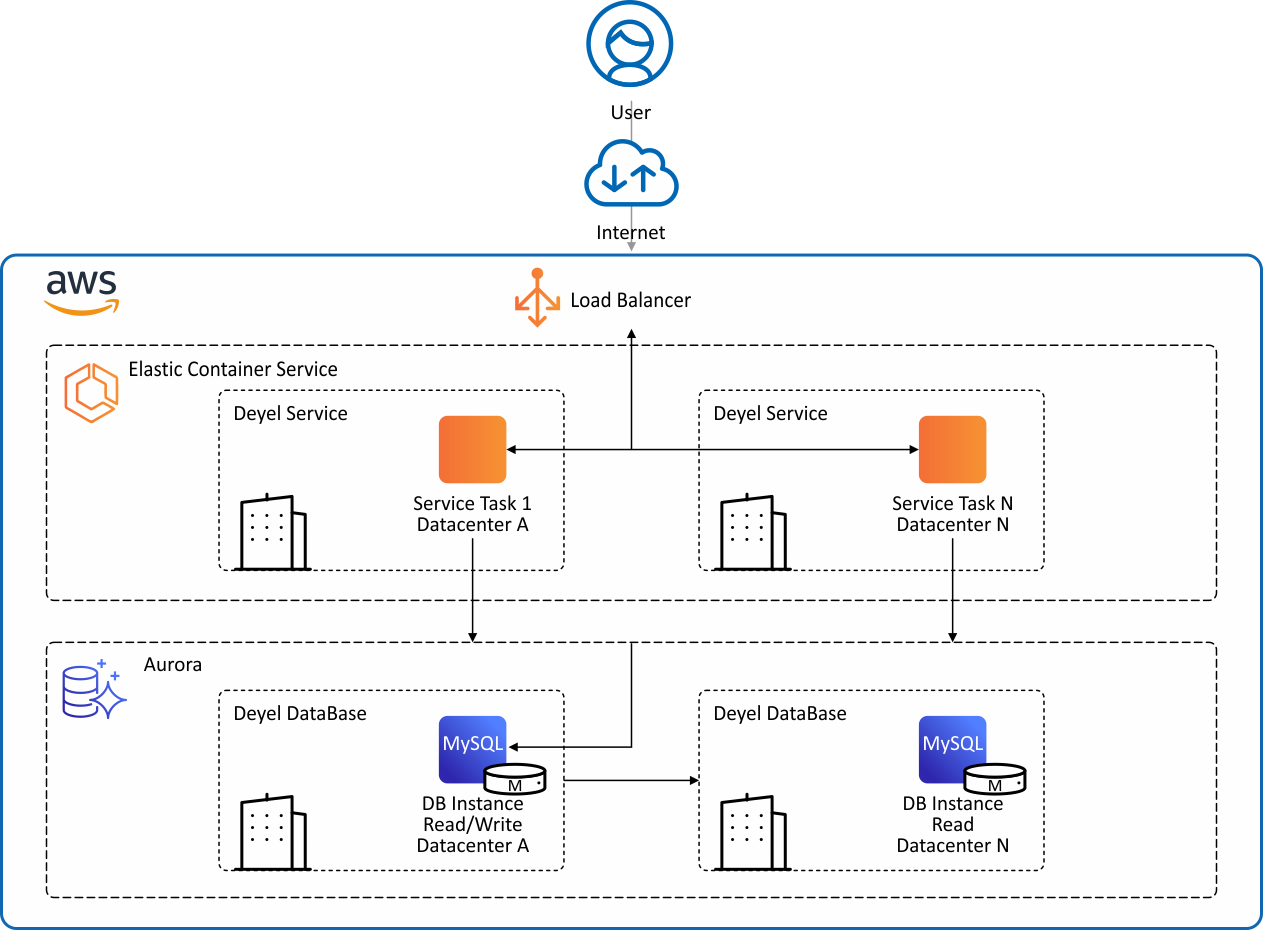
| Los datos de las aplicaciones se almacenan en clusters de Aurora del servicio Amazon Relational Database (RDS). Estos clusters están configurados con instancias de read/write y de read en diferentes zonas de disponibilidad, que pueden intercambiarse inmediatamente ante un eventual failover. |
| Para la creación de los backups se utiliza la opción multiAZ. |
•Ejecución de las aplicaciones
| Las aplicaciones se ejecutan en clusters del servicio AWS Elastic Container Service (ECS) con instancias EC2 distribuidas en zonas de disponibilidad, con autoescalado. Las aplicaciones se ejecutan en servicios de ECS y pueden ser multitarea distribuidas en instancias EC2 en distintas zonas de disponibilidad. |
| Los clusters utilizados por la infraestructura Deyel Cloud, pueden ser creados en cualquier región de AWS a nivel global en cuestión de segundos. |
•Archivos críticos de la infraestructura replicados entre regiones.
| Todos los archivos necesarios para el armado y creación de la infraestructura y para la recuperación de un desastre, están almacenados con el servicio de AWS S3 y Amazon ECR, usando replicación entre regiones. |
•Infraestructura como código (IaC)
La infraestructura y los recursos necesarios para la ejecución de Deyel en AWS se crean utilizando el servicio AWS CloudFormation. Al utilizar este servicio se cumple con las buenas prácticas de estandarizar los componentes de la infraestructura y se permite una rápida solución de problemas.
Suministra los recursos de las aplicaciones de una manera segura y repetible, ya que permite crear y recrear la infraestructura y las aplicaciones, sin tener que realizar acciones manuales ni escribir scripts personalizados.
A través de este servicio, la infraestructura Deyel Cloud y sus aplicaciones pueden ser implementadas en cualquier región de AWS a nivel global.
Eventos de Fallas, RPO y RTO para las Ediciones Standard y Enterprise
Las tareas y la base de datos con su réplica están en diferentes zonas de disponibilidad (en uno o más data centers) dentro de una región.
Evento de Fallas |
Acción |
RPO |
RTO |
|---|---|---|---|
El servidor que ejecuta la aplicación sale de servicio. Ejemplo: falla de hardware, placa madre, fuentes, discos, etc. |
Si se tienen varias tareas de la aplicación, se deriva la carga al resto. En todos los casos automáticamente se inicia una tarea idéntica en otro servidor del mismo data center. |
0 |
En la edición Enterprise el RTO es 0.
En la edición Standard el RTO es menor a 90 segundos. |
El data center que contiene los servidores que ejecutan la aplicación sale de servicio. Ejemplo: catástrofe en la ciudad del data center. |
Si se tienen varias tareas de la aplicación, se deriva la carga al resto. En todos los casos automáticamente se inicia una tarea idéntica en otro servidor de la misma zona de disponibilidad. |
0 |
En la edición Enterprise el RTO es 0.
En la edición Standard el RTO es menor a 90 segundos. |
El servidor que ejecuta la base de datos sale de servicio. Ejemplo: falla de hardware, placa madre, fuentes, discos, etc. |
Automáticamente la instancia que está solo de lectura se convierte en R/W. |
0 |
En ambas ediciones el RTO es menor a 90 segundos. |
La base de datos de R/W sale de servicio. (se rompe la estructura, problemas en el motor). |
Automáticamente la instancia que está solo de lectura se convierte en R/W. |
0 |
En ambas ediciones el RTO es menor a 90 segundos. |
Instancia de Réplica de Read en una Región Diferente a la Principal
La instancia de réplica de lectura en una región diferente a la principal es otra opción de mayor disponibilidad y tolerancia a fallas.
En el caso de considerar catástrofes de magnitud mundial en donde toda una región puede dejar de operar, se generan los clusters a través del servicio AWS CloudFormation en otra región y se continúa utilizando la base de datos interregional logrando una sincronización activa y una mayor tolerancia de fallas en base a una mejor dispersión geográfica.
El RTO mínimo indispensable es de 3hs, aunque se recomiendan tareas de verificación por parte del cliente antes de habilitar el uso de la plataforma nuevamente, que pueden elevar el RTO global.
A modo de ejemplo se detallan las tareas a realizar en estos casos.
Tareas |
RTO < 8 Hs |
|---|---|
Evaluación de la situación, verificación de la no operación de las regiones en donde estaba funcionando la plataforma. |
2hs |
Generación de la infraestructura de la plataforma en la tercera región. |
Menor a 30 minutos |
Configuración de la nueva infraestructura con la base de datos operativa en esta región. |
Menor a 30 minutos |
Verificación por parte del cliente de la plataforma. |
Recomendado. 3hs |




